Developer’s Perspective on IAC Tool
Managing cloud environments has become every day work for many, and it can either be a pleasant task or just a necessary evil. Increasingly, especially among those with a background in application development, people rely on Infrastructure as Code (IAC) tools. Whether it’s repeatability, self-documentation, security, automation, or any other selling point of IAC, this blog aims not to delve into those specifics. Instead, let’s focus on the tooling aspect and discuss what I’ve learned practically about the pros and cons of the relatively new CDKTF tool. Also, there’s an attempt to make the use of IAC less of a necessary evil and more of a meaningful task, without forgetting the essential benefits of IAC. These thoughts can be partially applied to other similar tools, emphasizing that relying on a single tool is not always necessary.
In large projects and in companies building extensive cloud infrastructures, there are often dedicated DevOps professionals with expertise in a specific tool, and switching those tools is usually unnecessary or impractical. However, there are situations where developers are responsible for building cloud infrastructure, and in such cases, DevOps tools may seem unfamiliar and may deviate from what a full-stack developer is used to. According to the 2023 Developer Survey on Stack Overflow, the majority of respondents (33.48%) identified themselves as Full Stack developers, whereas only 1.8% identified as DevOps specialists. So, the assumption that DevOps professionals will handle this seems quite uncertain, doesn’t it?
A New Wheel to Replace Many Old Ones?
As a Full Stack developer, I’ve often wondered why new languages need to be invented for so many purposes when there are plenty of old and proven ones available. Or why typical programming language structures are added to languages that were not originally intended for that purpose. Additionally, even though developers can proficiently use multiple programming languages nowadays, it’s not advisable to use more than necessary in the context of a single project to ensure things are done right. There’s already enough cognitive load in current projects and the world, even without constantly switching between several programming languages.
In various aspects of cloud infrastructure, you inevitably encounter languages mentioned loosely in the previous paragraph that are not meant for programming, such as JSON or YAML. Generally, these are used for configuration, and at their simplest, they are very straightforward. However, as needs increase, features and ways to ‘program’ them, such as templating, have emerged alongside or in addition to them. Terraform is one tool that has become almost a standard in many companies, and its associated language, according to HashiCorp, is a ‘configuration language’ (HCL) that falls into the category mentioned earlier. This is also a prime example of a configuration language where typical structures of traditional programming languages are incorporated simply because configurations are complex, and these features are needed.
While I’m not very experienced in the AWS realm, an alternative paradigm originating from this world, the AWS Cloud Development Kit (CDK), has gained some traction. And personally, I find it easy to fall in love with this model. All the years I’ve spent learning programming, figuring out how to do it cleanly so that it’s functional, testable, readable, reusable, and abstracted, have not been wasted. Now I can apply what I’ve learned to infrastructure development using a familiar, so-called ‘real’ programming language. As the cherry on top, I get to reminisce about the somewhat forgotten but in some way beautiful world of object-oriented programming, as functional programming takes over elsewhere. As a supporter of functional programming, I can say that building stacks as object models works very well for this purpose, as long as you don’t get too rigid thinking about the responsibilities of objects and creating complex inheritance hierarchies.
Now, with the CDKTF project, this paradigm is not only within reach for AWS developers, but the same model has been borrowed for HashiCorp’s new tool. The development of the library seems active, and so far, the version number 0.x.x does not promise stability in the interface. Disruptive changes may be expected between version updates. This may deter some from the tool, but having used it for a long time, I haven’t found updates problematic, and types assist in possible refactoring needs.
Types to the Fore
If you’re not ready to abandon old ways and are not convinced of the superiority of the CDK model, let’s try to explain why I personally find it meaningful. Before that, let’s look at CDKTF’s language options: Typescript, Python, Java, C#, and Go. So, there’s something for almost everyone, but I choose (and HashiCorp also recommends) Typescript. However, if everything else in the codebase is, for example, Java or C#, those would be good options. Again, for example, Python being a good language for many tasks, we immediately lose one crucial strength in this context: static typing. This, or rather its absence, is also one of the downsides of the original HCL language. So, in the context of this article, let’s forget about languages other than statically typed ones, and I’ll use Typescript in examples.
Even though the end result in IAC tasks, meaning the produced configuration, is not a functioning and running program where static types would provide security to eliminate runtime errors, types bring significant documentary benefits. Navigating back and forth through an IDE works much better with types, and the development cycle is faster when a whole bunch of simple errors are caught in type checking while writing them. Also, required properties don’t need to be dug from documentation because the IDE helps when the necessity of properties is visible from types.
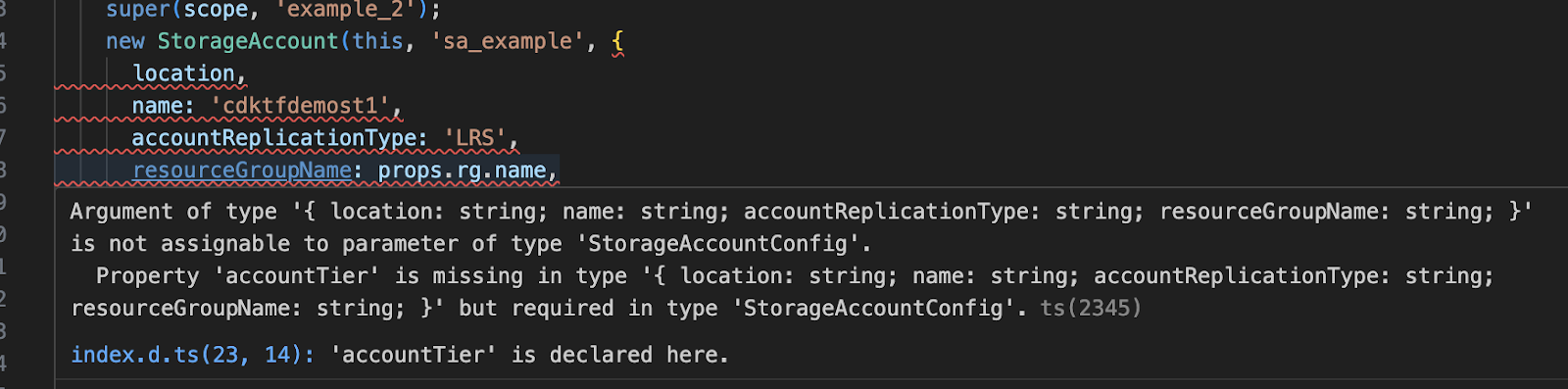
Especially diving into a large and complex Terraform codebase without types and clear dependencies is often a significant string-search exercise. The library already has many features that encourage the use of language capabilities. It must be noted that even though typed references can be used in many places, raw strings are still often used. This doesn’t have to be the case because the resource property is specified by the cloud platform to be one of certain string values, or allowed values may depend on another determining property. These could generally be typed.
The CDKTF equivalents of the Terraform providers (e.g., Azure or AWS resource APIs) are direct translations (and can be generated) from the originals, which is generally a good thing. For example, new provider versions and features don’t need to be implemented separately. Of course, there are weaknesses, such as the fact that these were not originally designed for a statically typed language, so type inference may not be very easily perfect. This could be different in a tool that is implemented from the ground up with static types, like Pulumi, but these differences need to be explored more thoroughly before I can analyze them in more detail. Let’s leave that for the next time.
Basic Structure and Simple Configuration
Before referring more to CDK-specific terms, let’s briefly go over some key points. An App instance is a special object, of which there is at least one, and it is where infrastructure content is assembled.
import { App } from 'cdktf';
const app = new App();
Code example: App object
In this, stacks are added, which are individual units with their own state files. Resources, on the other hand, correspond to infrastructure objects, and constructs are a way to form more abstracted entities, including multiple resources. So, in all simplicity, the process works by attaching various resources to stack objects, and the configuration is generated by passing it through the desired parameters.
const app = new App(); new ExampleStack(app); app.synth();
Code example: Adding a Stack
With these building blocks and the procedural statically typed language, you can build configurations quite elegantly. While in the HCL world, copy & paste coding is more the rule than the exception, with CDKTF, it doesn’t even cross your mind. Packaging things as your own construct or even your own functions is so easy. Similarly, adapting the same configuration to different environments is, once again, easier than with traditional methods. So, configuring the configuration 🙂 is a breeze. You can also use many of your favorite libraries, such as Envalid, and leverage many of the same practices as you do on the application side.
/** Using pre-build provider */
import { AzurermProvider } from '@cdktf/provider-azurerm/lib/provider';
import { ResourceGroup } from '@cdktf/provider-azurerm/lib/resource-group';
import { App, TerraformStack } from 'cdktf';
import { Construct } from 'constructs';
class ExampleStack extends TerraformStack {
/** Add resources in the constructor */
constructor(scope: Construct) {
/** Call base Constructor with id */
super(scope, 'example_1');
/** Add required providers */
new AzurermProvider(this, 'AzureRm', {
features: {},
subscriptionId: process.env.TF_ARM_SUBSCRIPTION_ID,
tenantId: process.env.TF_ARM_TENANT_ID,
});
/** Add resources to be created */
new ResourceGroup(this, 'rg_example', {
location: 'North Europe',
name: 'rg-cdktf-example',
});
}
}
const app = new App();
new ExampleStack(app);
app.synth();
Code example: Simplified Example
Now a simple CDKTF configuration is in place, and you can run the planning stage. yarn cdktf plan and you get output in the same format as with traditional HCL Terraform.
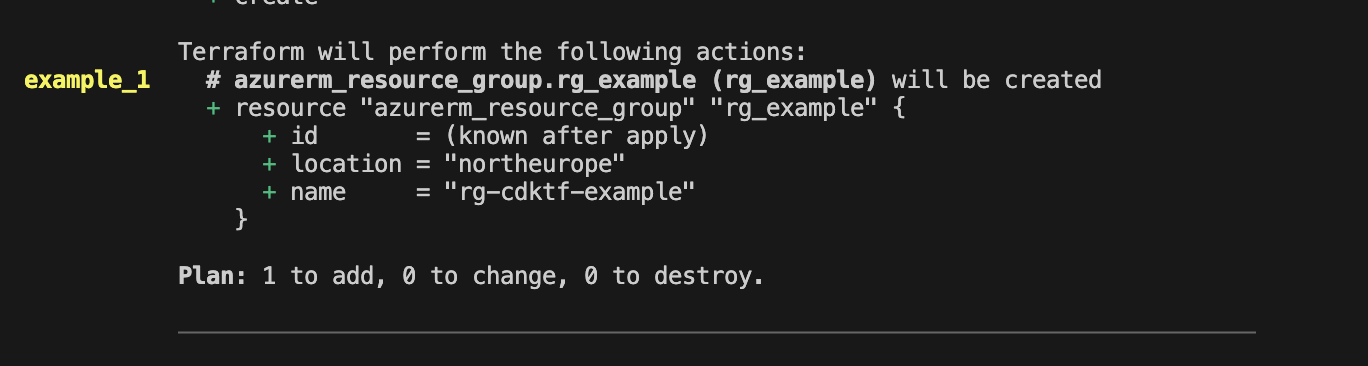
A lot of code for a single resource? Well, maybe, but we need more realistic use cases to bring out the benefits of typing and language. You start saving code when reusable parts come into play.
Configuration for Multiple Stacks
Using stacks, resources can be categorized into their own units, but often there are dependencies between them. This can be handled in many ways, but in Terraform, a separate output is often provided for the information you want to refer to from another configuration. In CDKTF, dependencies between stacks work like a charm when you don’t need to declare outputs separately. It’s enough to publish the resource as members from the stack where dependencies are coming from and directly use this object in another stack, as you might do in object-oriented programming. This could be compared to modeling dependencies in the data model used in an application.
Next, let’s add another stack to the previous example to illustrate this.
For each stack, you need to instantiate the necessary providers depending on what resources you want to use. Often, within one project, multiple stacks create resources using the same providers, so let’s first do a small refactoring to make this easier.
/** Base class for stacks using Azurerm provider */
abstract class ProviderStack extends TerraformStack {
constructor(scope: Construct, name: string) {
super(scope, name);
new AzurermProvider(this, 'AzureRm', {
features: {},
subscriptionId: process.env.TF_ARM_SUBSCRIPTION_ID,
tenantId: process.env.TF_ARM_TENANT_ID,
});
}
}
Code example: Abstract Base Class for Stacks
By adding an abstract base class, provider initializations can be handled in one place, and concrete resource stacks can focus on adding resources.
/** Using this in most resources */
const location = 'North Europe';
class ExampleStack extends ProviderStack {
public rg: ResourceGroup;
constructor(scope: Construct) {
super(scope, 'example_1');
/** Add resources to the scope of this stack using this keyword */
this.rg = new ResourceGroup(this, 'rg_example', {
location,
name: 'rg-cdktf-example',
});
}
}
class ExampleStack2 extends ProviderStack {
constructor(scope: Construct, props : { rg: ResourceGroup }) {
super(scope, 'example_2');
new StorageAccount(this, 'sa_example', {
location,
name: 'cdktfdemost1',
accountReplicationType: 'LRS',
accountTier: 'Standard',
resourceGroupName: props.rg.name,
});
}
}
const app = new App();
/** This stack needs to be created first */
const { rg } = new ExampleStack(app);
/** Depend on the output of the first stack */
new ExampleStack2(app, { rg })
/** Create the configuration */
app.synth();
Code example: Example with Two Stacks
Configuration Configuration
One idea in the IaC model is that it’s easy to deploy to many different environments. Usually, different environments serve different purposes: one is for testing, another for production, while a third might be for an entirely different client installation. In these cases, configuration needs to be adjustable in certain aspects.
Let’s address a few configuration-related things, and first, define all our environments, even though environments are not always so statically definable.
/** All possible azure environments */ export const ALL_ENVS = ['prod', 'test'] as const; export type Env = (typeof ALL_ENVS)[number];
Code example: Definition of Environments
Secondly, let’s add common things for several resources, such as tags, in one place.
/** Common configuration for resources, eg tags */
export const resourceDefaults = {
location: 'North Europe',
tags: {
configuredBy: 'cdktf',
project: 'demo'
}
}
Code example: General Configuration
Lastly, let’s define things that can vary between different environments. Add a config object that requires consideration for all different environments. At this point, environment variables could be used if there is a need to define things even more dynamically.
/** Things we may want to change between different environments */
export interface InfraConfig {
saTier: 'Standard' | 'Premium';
containers: { name: string, isPrivate?: boolean }[];
}
/** Configuration variations for all environments */
export const config: {
[key in Env]: InfraConfig;
} = {
prod: {
saTier: 'Premium',
containers: [
{ name: 'container1' },
{ name: 'container2', isPrivate: true }],
},
test: {
saTier: 'Standard',
containers: [{ name: 'container1' }],
},
};
Code example: Environment-Specific Configuration
Let’s modify our base class slightly by making the environment a parameter, thus achieving consistent naming.
abstract class ProviderStack extends TerraformStack {
constructor(scope: Construct, name: string, env: Env) {
super(scope, `${name}-${env}`);
Code example: Refactoring the Base Class
Finally, let’s illustrate the use of configuration with an example. The stack now requires not only a dynamic resource group reference but also our recently created configuration.
interface ExampleStack2Props {
rg: ResourceGroup;
}
class ExampleStack2 extends ProviderStack {
constructor(scope: Construct, env: Env, props : ExampleStack2Props & InfraConfig) {
super(scope, `example2`, env);
const sa = new StorageAccount(this, 'sa_example', {
...resourceDefaults, // spread defaults like tags
name: `cdktfdemost${env}`,
accountReplicationType: 'LRS',
accountTier: props.saTier, // from config
resourceGroupName: props.rg.name, // from another stack
});
//loop through
props.containers.forEach(({name, isPrivate}) => {
new StorageContainer(this, `container_${name}`, {
name,
storageAccountName: sa.name,
containerAccessType: isPrivate ? 'private' : 'container',
});
});
}
}
const app = new App();
/** Add all environments
* now we need to mention which stack we want run with cdktf */
ALL_ENVS.forEach((env) => {
const { rg } = new ExampleStack(app, env);
new ExampleStack2(app, env, {
...config[env],
rg
}
);
});
app.synth();
Code example: Utilizing Environment-Specific Configuration
Summary
Many great aspects have been left untold, and the use of custom construct classes could have been illustrated. However, through examples, the idea is hopefully conveyed that types are not written to add more code or make things cumbersome. Instead, it’s about bringing structure, self-documentation, security, and most importantly, reaping immediate benefits for development and refactoring through type checking. Programmability could also have been emphasized more. When you master the basic structures of the language, you don’t need to consult documentation for every loop or if statement; you can generally proceed as you’re used to elsewhere.
CDKTF isn’t suitable for everyone, but I believe it fits many. Personally, I’ve used both ways to implement Terraform: traditional HCL and CDKTF, and quite often, I’d choose the latter.